TAGE 分支预测算法
目前还没确定研究方向,但是学术论文写作课要求在自己的研究方向上寻找论文进行论文分享,完成一个长达 45 分钟的汇报。最终我还是兜兜转转选择了本科时期较为了解的处理器设计作为这次的论文寻找方向,正好拓展下处理器设计的技术,为后续辅导龙芯杯提供更先进的技术支持。
引言
在现代处理器设计中,分支预测器扮演着至关重要的角色,直接影响着处理器的性能。随着指令流水线的不断加深和处理器执行频率的提高,分支指令的错误预测会带来显著的性能损失。为应对这一挑战,计算机架构师们开发了多种分支预测技术,其中 TAGE(TAgged GEometric predictor)凭借其高精度和适应复杂工作负载的能力,成为当今最先进的分支预测方案之一。(目前主流的分支预测器都在 TAGE 算法的基础上进行优化,如 TAGE-SC-L 是在 TAGE 预测器上增加了 Loop Predictor 和 Statistical Corrector Predictor。后面如果有时间我也会对 SC 和 L 进行展开介绍。)
TAGE 预测器通过使用几何级数递增的历史长度和标记机制,能够在有限硬件资源下捕捉多层次的分支行为模式。这种设计不仅提升了分支预测的精度,还能够灵活适应各种程序中出现的短期和长期依赖模式。在本文中,我们将深入探讨 TAGE 分支预测器的工作原理、架构设计及其在现代处理器中的重要性。
目前这篇文章是基于大家已经了解了分支预测的原理,了解了基于局部历史的分支预测器以及基于全局的分支预测器的原理,掌握了经典的分支预测算法如自适应的两级分支预测器的基础上进行的讲解。后续如果有空我可能会在博客上补齐这些基础知识。
结构图
TAGE 预测器的灵感来源于 PPM-like(prediction partial matching)tag-based 预测器。
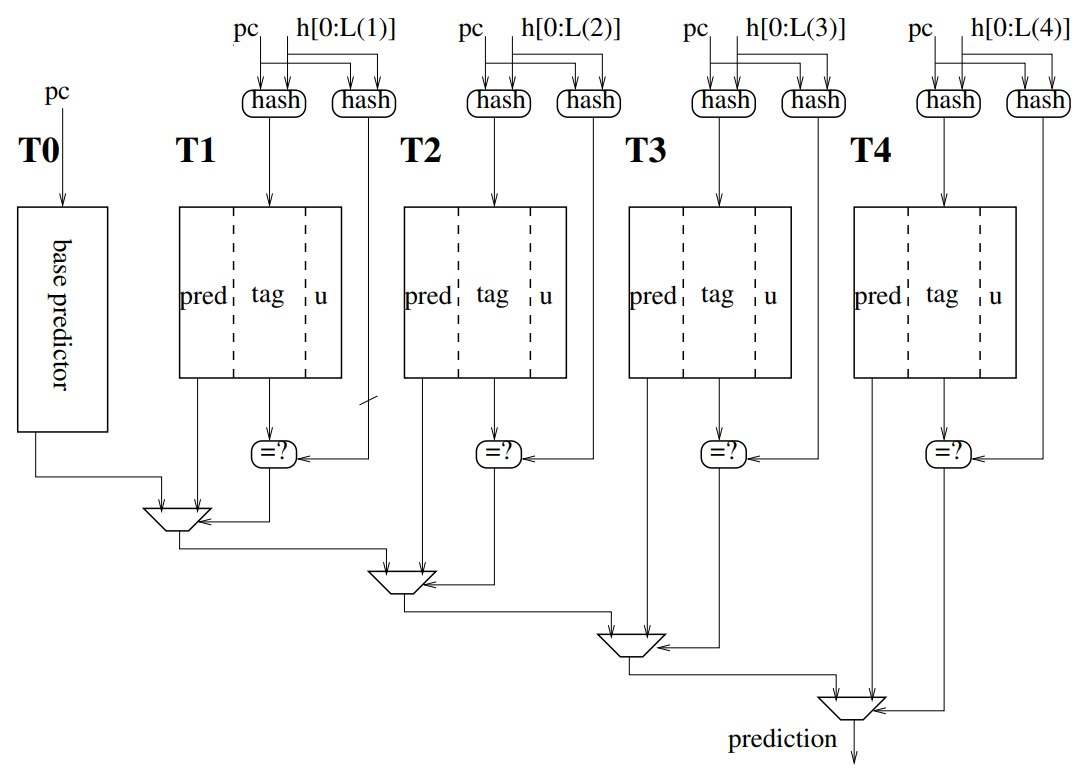
下面根据上图按照个人理解进行简要介绍,如有出入请及时联系我进行修改。
其中:
- 为当前需要预测的分支指令的地址
- 为一个全局分支历史寄存器,用于记录全局分支历史
- 表为使用 直接索引的表项,每个表项对应一个 2 位的饱和计数器(即使用 的 bit 索引 个表项的 Pattern History Table)
- 这 个表是使用 与对应的全局分支历史部分 进行哈希索引的表项,其中 , 为几何级数的比例因子
- 中每个条目包含 、 和 三个字段
- 为 3 位的饱和预测器,用于预测当前分支指令的方向
- 为 和 的哈希值,用于检索对应的表项。其中生成索引的哈希函数和生成 的哈希函数应当是不同的(由此可见 TAGE 表的构建类似缓存的组相联映射)
- 为宽度为 2 的 useful 计数器,用于表示当前项的使用率
- 由具有优先级的数据选择器选择得出
预测结果的获取
将 和 进行哈希运算得到 的索引 (每个表的哈希函数可以设计各异)。根据 读取每个表的表项,使用 判断是否命中。
当有多个命中时,使用 最大的表项作为预测结果:如当 和 都命中时,则使用 的表项作为预测依据。由于 是使用 直接索引的,因此 必定命中,可见当 都没命中时,将采用 作为结果。
需要注意的是,与 cache 的实现不同,TAGE 预测器的表项中只需要保证 命中即可( 与哈希值一致即为命中),无需 valid 位作为是否有效的保证,具体原因在读完下文后应该可以想到
符号说明
下面给出三个概念:
- provider component,:最终提供预测信息的表项
- final prediction,:最终提供的预测信息
- alternate prediction,:可供选择的预测信息表项。若命中的表项 ≥2,则 为命中的次长历史长度表项( 永远命中,且历史长度视为 0):如当 和 都命中时, 为 ;若仅命中 ,则 的预测表项也是 。
fpred 生成策略
在符号说明节中提到了三个概念,其中 和 均为提供预测信息的表项,而 为最终提供的预测结果,可见 和 两者 2 选 1 得到了 。
这种 2 选 1 的设计是为了避免在某些情况下,当更长分支历史信息的表项的信心不足时,使用 进行预测的成功率会更大。这种预测信心取决于设计时的定义,如将 3’b100 以及 3’b011 定义为弱信心,其他都为强信心;也可以定义仅 计数器饱和时为强信心,其他都为弱信心。
静态策略
即fpred 生成策略介绍的,当 为强信心时 选择 ,弱信心时选择 。
动态策略
使用一个有符号的 计数器来作为一个动态的阈值,来决定 信心不足时,最终预测结果的选择方式。 可以是单个计数器,也可以是一个计数器寄存器组,其使用分支指令的 直接索引。
- 的预测信息不为弱且 为负时,选择 ,否则选择 。
- 当 与最终的分支结果相同时, 递增,反之则递减(应当遵循饱和计算进行更新)。
useful 的更新
当 的预测结果与 不同时,需要更新 的 useful 计数器 ,即当 根据生成策略选择 且 的值与 不同时才需进行更新:
- 若 与最终的分支跳转结果相同时,则 递增 1
- 若 与最终的分支跳转结果不同时,则 递减 1
需要注意,对 useful 计数器的更新操作遵循饱和计算,即若 ,则递增 1 无作用;若 ,则递减 1 无作用。
同时,useful 计数器 还起到年龄计数器的作用,其 MSB(u[1])以及 LSB(u[0])会周期性的交替重置为 0。原文中的周期设置为每 256K 个分支指令进行一次重置操作。
上面的操作起到了类似 LSU 策略的效果。
预测正确的更新
如果 与最终的分支跳转结果相同,则对应的 根据最终的分支预测结果进行更新:
- 若最终的分支跳转结果为 taken,则 递增 1
- 若最终的分支跳转结果为 not-taken,则 递减 1
同样,对 的更新遵循饱和计算操作。
错误预测的更新
如果 与最终的分支跳转结果不同,则需要执行以下操作:
-
更新 ,其更新操作与预测正确时的更新操作相同
-
如果最终给出预测结果的表 ( 对应的表)不是使用最长全局分支历史信息的表(即 ,),则尝试往使用更长的全局分支历史信息的表上分配一个新的表项:
- 首先,读取所有比 使用更长全局分支历史信息表索引得到的表项的 的值
- (A)分配优先级:
- 如果存在 的值为 0 的 ,则将该表项分配使用
- 如果不存在 的值为 0 的 ,则所有比 使用更长的全局分支历史信息的表项的 值递减 1(这一步起到了类似 LSU 策略的效果)
- (B)避免 ping-phenomenon:
- 如果有 2 个或以上的表,如 ,,其中 即使用的全局分支历史长度都比 表长,且其索引得到的表项的 值都为 0,则优先分配全局分支历史长度短的表
- (C)初始化被分配的条目:
- 即将对应条目填入当前 和对应长度全局分支历史使用标签哈希函数生成的 ,将 初始化为对应的分支跳转结果,将 保持 0 不变(即 strong not useful)
其中策略 B 和策略 C 保证了存在多个未被分配的表时永远选择使用全局分支历史长度短的表进行替换,这可以最小化一些偶发性或者与分支历史不甚相关的分支指令占据过多的表项的现象。将 初始化为 0,能够保证该条目只有被多次访问具有准确预测结果时才能获得长时间不被替换的资格。这样也避免了乒乓替换的现象。
小节
经过上述流程的分析,已经明确了如何获取预测结果和更新方案,应该不难实现 TAGE 预测器的设计。在实际的处理器设计中,TAGE 预测器的表项数目、全局分支历史长度、几何级数比例因子等参数都需要根据具体的工作负载进行调整,以达到最佳的性能。