Sibyl--Adaptive and Extensible Data Placement in Hybrid Storage Systems Using Online Reinforcement Learning
本文为 ISCA’22 收录论文的精读笔记,该论文提出了首个面向混合存储系统、基于强化学习的自适应可扩展数据放置技术
写在开头
让我试试通过写博客的方式精读论文,希望这样能让论文阅读变得不那么枯燥
论文的链接为:https://dl.acm.org/doi/10.1145/3470496.3527442
Abstract
abstract 是 introduction 的总结与凝练
背景
混合存储系统(Hybrid storage system, HSS)使用多个不同的存储设备来提供高性能的高可扩展存储容量。跨不同设备的数据放置对于最大化这种混合系统的优势至关重要。
现有问题
现有的针对 HSS 的数据放置技术十分僵化,存在以下问题:
- 适应性差:既不能适配多样的工作负载(如从写密集型切换到读密集型、从随机访问切换到顺序访问),也不能适应设备特性变化(如设备读写延迟不对称性增强、设备类型 / 数量调整)
- 拓展困难:多数技术仅针对特定 HSS 配置(如 “快 + 慢” 双设备)设计,若要扩展到更多设备类型或数量(如 “快 + 中 + 慢” 三设备),需要重新设计
解决方法
- 解决适应性问题:能够持续学习负载特征以及设备特征,在线且自主的优化决策
- 解决拓展性问题:无需复杂重构,即可轻松适配不同类型的工作负载和 HSS 配置
其他优势
- 首个在 HSS 中,使用了强化学习的数据放置技术
- 在一个真实的系统中实现了 Sibyl,且该系统有多种不同的 HSS 配置
- 与四个数据放置技术进行了对比(包括基于启发式、机器学习)
- 在广泛的数据集,多种配置中进行验证(验证问题一)
- 变化存储器结构进行验证(验证问题二)
- 均优于 SOTA
- 使用了很小的成本,实现了很强的预测能力
Introduction
Introduction 是整篇文章的总结与凝练
这里我只列出在前面没提到的内容
目标
(1) adaptivity, by continuously learning from and adapting to the workload and storage device characteristics, and (2) easy extensibility to a wide range of workloads and HSS configurations.
该句在 Abstract 和 Introduction 中都有,且表述完全一致,整篇论文都是围绕该目标进行撰写:(1)适应性强,持续学习负载和设备特征;(2)易于扩展
核心思想
将数据放置设计成一个自主的强化学习 agent,可以根据负载(e.g.近期请求数目)和设备(e.g.剩余容量)的不同特征作为 state,根据 state 信息做出相应的 action(i.g.数据应该放哪个设备),每次的放置执行后,都会获得对应的 reward(reward 里封装了 HSS 的内部设备特性,例如读/写延迟、垃圾回收机制的延迟、排队延迟、错误处理延迟和写缓冲区状态)。Sibyl[1] 可以根据 reward 来估计其放置对设备性能的长期影响,并不断在线优化数据放置策略,从而最大化长期的 reward
这么做的好处
只需设计数据放置的性能目标,无需关注具体的放置策略的设计
数据放置模块会自学习到最佳的放置策略,减少了手动设计的负担
挑战
该部分先介绍了 challenge 是什么,接着给出了本文针对每个问题的解决方法
(1) Problem formulation
如何考虑 “存储设备的延迟不对称性”
- 设备内部不对称:同一存储设备的 “读延迟” 与 “写延迟” 不同(例如,SSD 的写延迟通常高于读延迟,HDD 的随机写延迟远高于顺序读延迟);
- 设备间不对称:不同类型设备的整体延迟差异显著(例如,Optane SSD 的读延迟约 10μs,而 HDD 的读延迟约 10ms,相差 1000 倍),且这种差异会因设备状态动态变化
真实存储设备的延迟并非固定值,而是受硬件 / 软件组件动态影响:比如 SSD 的 “垃圾回收” 会临时增加写延迟,HDD 的 “寻道时间” 会因访问位置不同波动,存储设备的 “内部缓存命中 / 未命中” 也会导致延迟突变
若 RL 智能体无法感知这些不对称性与动态变化,会做出错误决策:例如,误将 “写密集数据” 放入 “写延迟极高的设备”,或因未察觉设备延迟突然升高而继续将关键数据放入该设备,最终导致系统性能下降
如何解决 “信用分配问题(Credit Assignment Problem)”
RL 的核心逻辑是 “通过奖励 / 惩罚引导智能体学习最优动作”,而 “信用分配” 指:如何将最终的奖励 / 惩罚,合理归因到之前的一系列决策动作上。例如,若系统最终出现性能下降,需判断是哪个(或哪些)之前的放置决策导致的,才能正确惩罚;若性能提升,也需明确哪个决策是关键,才能正确奖励
HSS 中,“快存(如 Optane SSD)容量有限” 是核心约束 —— 当快存剩余容量不足时,会触发 “后台驱逐”(将快存中部分数据迁移到慢存)。这种驱逐会导致两个问题,直接加剧信用分配难度:
- 奖励的 “延迟性”:当前的 “将数据放入快存” 决策,可能不会立即引发问题,但后续快存满时,该数据被驱逐会导致额外延迟 —— 此时难以判断 “驱逐的惩罚” 该归因于 “当前放置决策”,还是 “更早的其他放置决策”;
- 奖励的 “可变性”:驱逐的开销(如迁移耗时)会因 “被驱逐数据的大小”“慢存当前负载” 而变化,导致同一放置动作可能在不同场景下引发不同的惩罚,进一步增加 “哪个动作该奖 / 该罚” 的判断难度
(2) 实现的开销
一个工作负载可能有数十万页的存储数据,这使得以低设计开销有效处理大量数据占用成为一项挑战
在 Introduction 中列出难点后就可以引出本文的解决方法
应对挑战一:1.设计以请求延迟为核心、含驱逐惩罚的奖励结构,助力学习设备特性与解决信用分配问题;2.通过超参数调优,适配多样工作负载
应对挑战二:1.将状态分箱以压缩状态空间;2.用轻量级前馈神经网络,替代表格型 RL 以降低开销
结果
下面列出了测试环境:
- 使用两种不同的双 HSS 配置和两种不同的三 HSS 配置
- 使用在真实企业服务器上收集的来自 Microsoft Research Cambridge(MSRC)的 14 种不同的存储跟踪
- 在 FileBench 中使用未训练过的工作负载
- 对比了 4 个 state-of-the-art 数据放置技术
覆盖了广泛的负载、多种 HSS 配置,可以测出前面提到的 Sibyl 的特点,也达到了测试效果,凸显了性能
贡献
列了 5 个贡献:
- 验证现有技术缺陷:在真实 HSS 上证明,当前主流数据放置技术因缺乏对工作负载变化、设备特性的适应性及可扩展性,性能远不及先知(Oracle)策略
- 提出 Sibyl 机制:设计首个基于强化学习(RL)的 HSS 自优化数据放置技术,能结合多工作负载特征与系统反馈,动态调整策略以优化长期性能
- 深入真实系统评估:在多种 HSS 配置(双设备、三设备)下开展评估,证明 Sibyl 在多样应用场景中均优于 4 种主流技术,且实现开销低
- 解释决策逻辑:深入剖析 Sibyl 的决策机制,证实其能通过学习设备读写延迟不对称性、设备数量/类型变化,实现动态数据放置
- 开源助力研究:免费开源 Sibyl,为存储系统数据放置领域的后续研究提供支持
Background
Hybrid Storage Systems (HSSs)
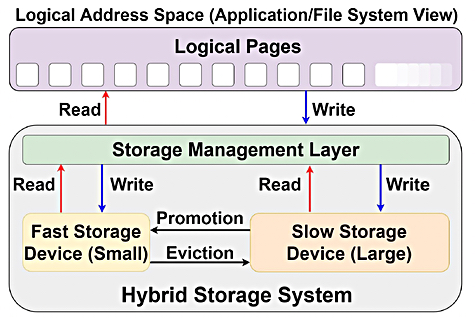
- HSS 的设备组成
- 传统 HSS 由小容量高速度存储设备(如 NAND 闪存 SSD)和大容量低速度存储设备(如 HDD)构成;
- 现代 HSS 则多整合新兴非易失性存储器(NVM)与低速高密度 NAND 闪存设备,兼顾性能与存储规模。
- 存储管理层的部署与功能
- 部署位置分为两类:一是主机系统的系统软件,二是混合存储设备的固件(如闪存 SSD 的闪存转换层 FTL);本文方案在操作系统存储管理层实现;
- 该层通过 NVMe 或 SATA 接口协调异构设备 I/O 请求,对外提供统一逻辑地址空间(类似 Linux 的 md 内核模块),可将逻辑页的读写操作映射到具体存储设备。
- 数据迁移机制
- 提升(promotion):当慢速存储中的数据页面被频繁访问时,会被迁移至快速存储,降低后续访问延迟;
- 驱逐(eviction):当快速存储内数据访问频率过低,或快速存储容量耗尽时,数据会被迁移至慢速存储,保障快速存储资源用于高价值数据。
- HSS 性能的核心影响因素
存储管理层对异构设备和多样工作负载的管理能力,理想的数据放置策略需同时实现:- 充分发挥快速设备低延迟优势;
- 优化其小容量资源的利用率;
- 具备对各类工作负载和 HSS 配置的可扩展性。
Reinforcement Learning
原文该节是专门放在强化学习一节中,这里我把他放到背景里一并介绍掉
- RL 的基本交互框架
强化学习是一类机器学习算法,其核心是智能体(agent)与环境的持续交互。智能体从初始状态(为所有可能状态的集合)出发,在每个时间步会执行一个动作(为所有可能动作的集合),并由此转移至下一个状态;同时,智能体会因该动作获得一个数值型奖励,奖励可即时或延迟发放。从初始状态到最终状态的一系列“状态-动作”序列被称为 episode,智能体的决策目标是最大化整个交互过程中的累积奖励(return),而非单一步骤的奖励。 - 策略与最优目标
策略定义了智能体在特定状态下的动作选择规则,其核心目标是找到最优策略。最优策略的获取依赖于计算最优动作价值函数(即 Q 值),代表在状态下执行动作能获得的期望累积奖励,通过优化该函数可确定最优动作。 - 传统 RL 方法的局限
传统 RL(如 Q-learning)采用表格型方法,通过查找表存储所有状态-动作对对应的 Q 值。但当状态或动作空间规模较大时,这种方法会产生极高的存储和计算开销,难以适配复杂场景。 - 解决方案:价值函数近似
为解决表格型方法的局限,研究提出价值函数近似技术,用监督学习模型替代传统查找表。该技术可对大量状态-动作对进行泛化处理,在保证决策效果的同时,大幅降低存储与计算开销。
Motivation
-
评估实验设置
- 评估对象:包含两类基线技术,一是启发式技术(冷数据驱逐 CDE、基于历史的页面选择 HPS),二是机器学习技术(神经网络分类器 Archivist、基于循环神经网络的 RNN-HSS);同时引入 3 个极端基线(仅慢速存储 Slow-Only、仅快速存储 Fast-Only、全知未来访问模式的 Oracle)作为参照。
- 存储设备与配置:采用高端(H)、中端(M)、低端(L)三类存储设备,搭建两种 HSS 配置(性能导向 H&M、成本导向 H&L),并将快速存储容量限制为工作集的 10%,确保触发数据驱逐以验证策略有效性。
- 工作负载:基于 14 个 MSRC 企业服务器存储轨迹,分析其热度(以页面平均访问次数衡量)与随机性(以平均请求大小衡量)特征,验证负载的多样性与动态性。
-
现有技术的核心缺陷
- 缺乏适应性
- 对工作负载变化的适配不足:现有技术仅考虑有限的负载特征,且参数为设计阶段静态调优,无法应对动态负载需求。实验显示,基线技术相对 Oracle 的平均性能损失最高达 41.1%,且无单一策略能适配所有负载;同时负载的热度、随机性差异显著且存在动态波动(如 rsrch_0 负载的访问地址和请求大小随时间变化明显),现有策略无法持续跟进。
- 对设备类型/配置的适配不足:现有技术无法兼顾设备读写延迟不对称、数据迁移成本等特性。例如在 H&M 配置中,CDE、HPS 等基线对 hm_1、prn_1 等负载的性能甚至劣于 Slow-Only;而在 H&L 配置中基线性能相对更优,体现出设备特性对策略效果的强影响,且现有方案无法整体适配。
- 缺乏可扩展性
现有技术多为双设备 HSS 设计,而现代 HSS 已支持三设备及以上配置。扩展时需架构师额外投入大量精力(如基于 CDE 的三设备策略需静态定义数据热度阈值、手动处理三设备间的升降级逻辑),且扩展后的启发式策略性能劣于 RL 方案,相对性能损失最高达 48.2%。
- 缺乏适应性
-
研究动机的落脚点
现有技术的刚性缺陷(适配性不足、扩展性差),迫切需要一种能持续学习并适配负载与设备特性、易于扩展至多设备 HSS 配置的新型数据放置技术,为后续基于强化学习的 Sibyl 方案提供了核心研发依据。
RL Formulation
该节的核心是将混合存储系统(HSS)的数据放置问题转化为标准 RL 问题,明确 RL 智能体(Sibyl)与环境(HSS)的交互逻辑,定义三大核心要素:
-
奖励函数(Reward) - 设计逻辑:奖励值基于请求延迟和驱逐惩罚计算,核心目标是最小化平均请求延迟,同时避免因非热点数据占用快速存储导致的频繁驱逐。 - 计算公式:无驱逐时,奖励(为当前请求服务延迟,延迟越低奖励越高);存在驱逐时,奖励(为驱逐惩罚,取值为,为驱逐操作耗时,以此约束智能体仅将性能关键数据放入快速存储)。
observation vector 如下: -
状态特征(State)
- 特征选择:构建 6 维观测向量,分别对应请求大小、请求类型(读/写)、页面访问间隔(两次访问同一页面间访问其他页面的次数)、页面访问次数、快速存储剩余容量、数据当前存储位置。
- 特征优化:对每个特征进行分箱量化(如请求大小分 8 个箱、访问间隔分 64 个箱),既降低状态空间规模和存储开销,又保留核心决策信息。
-
动作空间(Action)
- 双设备 HSS 配置下,动作仅包含“放入快速存储”和“放入慢速存储”两类;可无缝扩展至三设备及以上配置,仅需增加对应动作维度,体现技术的可扩展性。
Design
该部分基于 RL 建模,完成 Sibyl 的架构与流程设计,核心是双线程并行架构和轻量化网络设计,兼顾决策实时性与策略优化效率:
- 整体架构:双线程并行设计
- RL 决策线程:负责实时生成数据放置决策,同时收集“状态-动作-奖励-下一状态”形式的经验并存入经验缓冲区,不参与模型训练,保障决策低延迟。
- RL 训练线程:基于经验缓冲区的历史数据,异步更新训练网络权重,每处理 1000 个请求后将训练网络权重同步至推理网络,避免训练阻塞决策流程。
- 核心算法流程(Algorithm 1)
- 初始化:分配容量为的经验缓冲区,将训练/推理网络权重初始化为随机值;
- 决策阶段:采用-greedy 策略(),以概率选择推理网络输出的最优动作,以概率随机探索;
- 经验存储:执行动作后收集奖励,将完整经验存入缓冲区;
- 模型训练:当缓冲区存满 1000 条经验时,随机采样批次数据,通过随机梯度下降(SGD)更新训练网络权重,并定期同步至推理网络。
- 关键模块设计
- 经验缓冲区:部署于主机 DRAM,单条经验占 100 比特,1000 条经验仅需 100 KiB 开销,支持数据去重和经验回放,提升训练数据质量;
- 双网络架构:推理/训练网络均为轻量级前馈神经网络(输入层 6 神经元、隐藏层 20/30 神经元、输出层神经元数与动作空间匹配),采用 swish 激活函数,在 CPU 上即可实现低延迟推理(单次推理仅需 10ns)和训练(单次训练仅需 2us);
- 超参数调优:通过交叉验证+实验设计(DoE)确定最优超参数组合(折扣因子、学习率、批次大小 128 等),且仅需一次性离线调优,即可在线适配各类负载。
Evaluation
每个实验都得服务于论文主旨——(1)适应性;(2)易于扩展
实验如下:
- 性能测试:在 MSRC benchmar 上选了 14 个数据集进行测试;测试了延迟和吞吐量
- 使用未进行过超参调优的测试集进行测试,使用了 4 个 FileBench 进行测试;是为了避免由于超参调优的干扰,所以使用了从未测试过的测试集
- 混合测试集,把 2 个甚至更多的数据集和在一块测试;这样子更能展示论文的方法的灵活性
- 选用对比系统使用的特征,展示特征选用对系统性能的影响
- 使用不同的超参进行测试
- 使用不同 Fast Storage 容量进行测试
- 测试 Tri-Hybrid 存储系统
Explainability Analysis
该节的核心目标是打破强化学习(RL)模型“黑盒”决策的局限性,通过分析 Sibyl 在不同混合存储系统(HSS)配置和工作负载下的数据放置行为与驱逐情况,阐释其决策逻辑的合理性与适配性,具体内容分为两部分:
Sibyl 对快速存储的放置偏好分析
为量化 Sibyl 的放置倾向,作者定义了快速存储偏好系数
即快速存储中数据放置次数占总放置次数的比例,结合论文图 17 的实验数据,得出以下 4 个核心结论:
- 适配存储设备的延迟差异
- 在 H&L 配置(高端存储 H 与低端存储 L,设备间延迟差距大)中,Sibyl 会显著提高快速存储的放置比例。因为即使存在驱逐惩罚,将数据放入低延迟的 H 设备所带来的整体性能收益,远大于驱逐操作的额外开销;
- 在 H&M 配置(高端存储 H 与中端存储 M,设备间延迟差距小)中,Sibyl 仅将性能关键数据放入快速存储。此时若盲目抢占快速存储空间,会因频繁驱逐引发额外延迟,反而抵消性能优势,因此 Sibyl 会主动控制快速存储的放置比例以规避该问题。
- 适配工作负载的热度与访问模式
- 对于冷且顺序型负载(如 mds_0、prn_1、proj_2 等),Sibyl 会降低快速存储放置偏好。这类负载数据访问频次低、请求规模大,放入慢速存储不会显著影响性能,还能为热数据预留快速存储空间;
- 对于热且随机型负载(如 prxy_0、prxy_1),Sibyl 会提高快速存储放置偏好。这类负载数据访问频次高、请求地址离散,放入快速存储可大幅降低随机访问的延迟损耗。
- 适配负载的特殊访问特征
对于 rsrch_0、wdev_2、web_1 等负载,Sibyl 仅将 ≤40%的页面放入快速存储。原因是这类负载虽存在随机访问,但整体访问频次偏低,且包含大量冷数据,过度占用快速存储会引发无效驱逐,因此 Sibyl 会平衡放置比例。 - 适配负载的访问频次与随机性平衡
在 H&L 配置中,Sibyl 对大部分负载都倾向于快速存储放置,但 proj_2、src1_0 是例外。这两类负载虽随机性高,但平均访问次数极低,即便放入快速存储,也无法通过高频访问摊薄放置成本,因此 Sibyl 会选择将其放入慢速存储。
Sibyl 与 baseline 的驱逐情况对比
作者还统计了 Sibyl 与其他 baseline 的驱逐比例(驱逐次数占总存储请求数的比值,见图 18),得出 2 个关键结论:
- H&M 配置下的低驱逐优势
在 H&M 配置中,Sibyl 的驱逐比例远低于其他基线:相比 CDE、HPS、Archivist、RNN-HSS,驱逐次数分别减少 68.4%、43.2%、19.7%、29.3%。这印证了 Sibyl 在设备延迟差距小时,能精准识别性能关键数据,避免因无效数据占用快速存储而引发的频繁驱逐。 - H&L 配置下的策略适配性
在 H&L 配置中,Sibyl 的驱逐比例有所上升,甚至接近 CDE 的水平。这是因为 H&L 设备延迟差距极大,此时“优先抢占快速存储空间”是更优策略——即使引发一定驱逐,快速存储带来的访问延迟收益也能覆盖驱逐开销,这体现了 Sibyl 对极端设备配置的动态策略适配。
Overhead Analysis
论文不仅要讲述优点,还需要分析下开销
Inference and Training Latencies
该部分先明确 Sibyl 的神经网络基础架构,再分别测算推理和训练的耗时,论证其延迟远低于存储设备的 I/O 延迟,不会影响系统整体性能。
-
神经网络基础架构参数
- 输入层:6 个神经元,与 Sibyl 的 6 维状态特征(请求大小、类型、访问间隔等)一一对应,输入前会对特征做归一化和低精度转换以缩减内存占用;
- 隐藏层:2 层全连接层,分别包含 20、30 个神经元,用于提取特征关联;
- 输出层:神经元数量与动作空间匹配(双设备 HSS 为 2 个、三设备 HSS 为 3 个),输出各动作的 Q 值分布;
- 状态编码:单个状态条目为 40 比特(32 比特状态特征+8 比特快速存储剩余容量计数器),兼顾信息完整性与存储效率。
-
推理延迟
- 计算量:推理网络共 52 个神经元(20+30+2)、780 个权重,单次推理需执行 780 次乘累加(MAC)操作;
- 耗时:在测试 CPU 上仅需~10ns 即可完成,而高端 SSD 的 I/O 读延迟约为~10us,二者相差 3 个数量级;
- 部署灵活性:推理计算不仅可在主机 CPU 执行,还能迁移至 SSD 控制器,进一步降低主机侧开销,且完全不影响存储请求的响应效率。
-
训练延迟
- 计算量:单次训练步骤需处理 8 个批次(每批次 128 条经验),总计需 1,597,440 次 MAC 操作;
- 耗时:在测试 CPU 上仅需~2us;
- 无性能干扰的原因:一是训练与推理异步执行,训练过程不阻塞实时数据放置决策;二是训练延迟仅为高端 SSD 读延迟的 1/5,不会抵消 Sibyl 的性能收益。
Area Overhead
该部分从主机 DRAM 存储开销和元数据开销两个维度,证明 Sibyl 的资源占用可忽略不计。
-
主机 DRAM 存储成本
- 网络权重开销:训练和推理网络的权重均采用 16 比特半精度浮点格式,单个网络 780 个权重需 12.2 KiB 内存,双网络合计 24.4 KiB;
- 经验缓冲区开销:1000 条经验的缓冲区需 100 KiB(单条经验 100 比特);
- 总开销:二者相加仅需 124.4 KiB DRAM,相较于现代服务器 GB 级的内存容量,占比可忽略。
-
元数据成本
- 元数据规格:Sibyl 需为每 4 KiB 数据存储 40 比特(5 字节)的状态信息(即表 1 的 6 维特征);
- 开销占比:该元数据仅占总存储容量的~0.1%,对存储系统的可用空间几乎无影响。
Dissccussion
该章节是对 Sibyl 技术的局限性反思、核心价值阐释及未来拓展方向探讨
Cost of generality(通用性的代价:Sibyl 的局限性)
这部分客观指出了基于强化学习(RL)实现数据放置的两大核心短板:
- RL 模型的“黑盒”属性
- 目前 RL 本质上是黑盒决策机制,尽管论文第 9 节的可解释性分析已尝试拆解其决策逻辑,但要实现严格的、可量化的决策解释仍存在技术壁垒(该方向属于 RL 领域的前沿研究课题,超出本文研究范畴)。
- 由于决策的动态性和复杂性,无法精准定位 RL 策略的“最差工况负载”,也难以用人类可理解的规则完全建模其决策逻辑。
- 工程实现的额外成本
- 需投入大量工程精力完成 RL 超参数调优,确保参数适配多类负载和存储配置;
- 需将 Sibyl 组件集成到主机操作系统的存储管理层,该集成过程的技术门槛和适配成本并非可忽略,且这类成本是所有 ML-based 存储管理技术的共性问题(但 Sibyl 的存储和延迟开销已被量化为极低水平,可抵消部分工程成本)。
Sibyl’s implications(Sibyl 的核心价值与意义)
该部分明确了 Sibyl 技术对混合存储系统(HSS)领域的三大关键价值:
- 泛化性的性能提升
实验验证表明,Sibyl 在各类负载和存储配置下,均能超越现有主流数据放置策略,实现稳定的性能增益,打破了传统策略“仅适配特定场景”的局限。 - 降低多设备配置的设计负担
其 RL 架构具备天然可扩展性,无需架构师为多设备 HSS(如三设备配置)重新设计复杂的启发式规则,大幅减轻了新型存储配置的研发成本。 - 缩减快存硬件成本
由于 Sibyl 能精准识别性能关键数据、最大化快存资源利用率,因此可在保证系统性能的前提下,降低对快存硬件容量的需求,实现“小容量快存+高效策略”的低成本 HSS 方案。
Adding more features and optimization objectives
RL 架构的灵活性让 Sibyl 具备功能拓展的潜力,核心阐述了两个拓展方向:
- 新增状态特征
可在 RL 状态向量中加入新特征(如带宽利用率),无需重构整体策略框架,RL 智能体可自主学习新特征的决策价值。 - 多目标优化
传统方案仅优化“请求延迟”,而 RL 可通过重构奖励函数实现多目标协同优化:- 若需优化设备耐久性,可将“耐久性敏感设备的写入次数”纳入奖励函数;
- 若需兼顾性能与能耗,可设计复合奖励(如延迟权重+能耗权重),让智能体自主平衡多目标优先级(该方向为未来研究重点)。
Necessity of the reward
RL 的训练效果高度依赖奖励函数设计,论文通过对比两种“替代奖励方案”,验证了现有奖励函数的最优性:
- 以快存命中率为奖励的缺陷
若仅追求快存命中率,Sibyl 会盲目将数据放入快存,引发大量无效驱逐,且无法适配存储设备的读写延迟不对称性(如 SSD 的垃圾回收延迟、队列延迟等),最终导致系统整体性能下降。 - 以“驱逐高负奖励”为核心的缺陷
若仅对驱逐行为施加高惩罚、其他场景无奖励,Sibyl 会过度保守地将数据放入慢存,完全浪费快存的低延迟优势,无法发挥 HSS 的架构价值。 - 现有奖励的合理性
基于“请求延迟+驱逐惩罚”的奖励函数,既能通过延迟反馈感知系统状态,又能约束快存的无效占用,经多负载验证可适配绝大多数 HSS 场景。
Managing hybrid main memory using RL
该部分分析了 Sibyl 核心思想迁移至混合主存管理的可行性与挑战:
- 可行性
混合主存与混合存储的核心问题均为“异构介质的数据放置”,RL 的自适应和可扩展特性可复用至该场景。 - 核心挑战
混合主存对决策延迟的要求远高于存储系统(主存访问延迟为纳秒级,存储为微秒级),Sibyl 现有的推理和训练延迟需进一步压缩,才能适配主存的低延迟管控需求;此外,论文因存储系统的“低单位成本”和“大数据集适配”优势,优先聚焦存储领域,将混合主存的 RL 方案留作未来研究。
- Sibyl 是希腊神话中预言准确的神谕,而本文的目标也是实现一个预测准确的数据放置技术 ↩