RISC-V Sv39
最近在设计实现 RV64 的 S 模式,而 S 模式的核心就是虚实地址转换的实现,只要把虚实地址转换部件设计好了,S 模式也就实现的大差不差了
下面是基于我的 RV64 核的虚实地址转换硬件实现以及 RV 手册进行的介绍,可能有许多简化以及缺失的部分,忘见谅
对比 MIPS
在 MIPS(龙芯杯团队赛的 MIPS 指令集)的实现中,首先虚拟内存的地址划分是固定死的:哪些段是直接映射,哪些段是需要虚实地址转换,哪些段是可缓存的,这些都在手册里写的很清楚。而 RISC-V 并没有对这些进行详细的描述,在我的设计中,属于 MMIO 的都为 uncached 段,可以自由配置 MMIO 空间;而是否需要虚实地址转换则由 satp 寄存器的 mode 域指示
TLB(Translation Lookaside Buffer) 的重填也有区别,MIPS 的实现很简单,我们只需要实现了 TLB 的相关指令即可,剩下的交给 OS(Operating System),OS 会为我们自动填 TLB 等;而对于 RISC-V,假如发生了 TLB miss 则需要硬件自己完成 TLB 的重填,负责重填的部件叫做 PTW(Page Table Walker),由它访问页表并对 TLB 进行填充;虽然重填操作由软件实现或硬件实现在使用上几乎没差别,但是对于硬件设计者来说后者肯定要设计更多部件,工作量会更大一些(🙁)
satp 寄存器
全称是 Supervisor address translation and protection,在 CSR 中的地址为 0x180。处理器通过这个部件进行内存分页的控制
在 RV64 中其结构如下:
1 | |
PPN(Physical Page Number):保存根物理页表的物理地址,实际值为根页表物理地址右移 12 位(因为每页大小为 4KB,所以低 12 位为 0,没必要写入 satp)
ASID(Address Space Identifier):用于在虚拟内存系统中区分不同的地址空间,也是和 TLB 需要比对的值之一
MODE:用于选择分页模式,值为 8 时启用基于 Sv39 的地址转换
1 | |
活动性判定
只有当前运行在 S 或 U 模式时,才能认为 satp 是活动的
地址转换是否开启
下面两个条件均满足时,需要进行地址转换
-
当前的模式是否是 S 或 U 模式
-
MODE 位的值是否为 8
虚拟地址
Sv39 下,虚拟地址宽度为 39bit。VPN 的总宽度为 27
1 | |
VPN[2,1,0]:用于在多层页表中进行索引查询
使用方法详见 虚实地址转换过程
物理地址
我的 CPU 核的 AXI 总线地址宽度为 32bit,因此物理地址位宽为 32bit
PPN 的总宽度为 20,同时也是 Cache 中 tag 的宽度(Cache 采用 VIPT 策略)
1 | |
PPN[2,1,0]:没必要分开使用,只要合在一起作为物理地址即可
内存页表项
简称 PTE(Page Table Entry)
1 | |
V:是否有效。如果为 0,则不考虑 PTE 中的所有其它位,其它位可以由软件自由使用
R:是否可读
W:是否可写
X:是否可执行
当 R、W、X 这三个位都为零时,PTE 是指向页表下一级的指针;否则,它是一个叶 PTE。可写页面也必须被标记为可读;其相反的组合被保留供将来使用
| X | W | R | Meaning |
|---|---|---|---|
| 0 | 0 | 0 | Pointer to next level of page table |
| 0 | 0 | 1 | Read-only page |
| 0 | 1 | 0 | Reserved for future use |
| 0 | 1 | 1 | Read-write page |
| 1 | 0 | 0 | Execute-only page |
| 1 | 0 | 1 | Read-execute page |
| 1 | 1 | 0 | Reserved for future use |
| 1 | 1 | 1 | Read-write-execute page |
尝试从没有执行权限的页面获取指令时,会引发 Instruction page fault 异常。尝试执行有效地址位于没有读取权限的页面内的加载或加载保留指令时,会引发 Load page fault 异常。尝试执行有效地址位于没有写入权限的页面内的存储、存储条件或 AMO 指令时,会引发 Store/AMO page fault 异常
U:是否可被 U 模式访问
如果设置了 sstatus 的 SUM 位,则 S 模式也可以访问 U 为 1 的页面。但是,S 模式代码通常在 SUM 位清除的情况下运行,在这种情况下,S 模式代码将在访问用户模式页面时引发对应访问类型的异常。无论 SUM 如何设置,S 模式都不能在 U 为 1 的页面上执行代码
G:是否全局映射
全局映射是存在于所有地址空间中的映射。对于非叶 PTE,全局设置意味着页表后续级别中的所有映射都是全局的。请注意,未将全局映射标记为全局映射只会降低性能,而将非全局映射标记为全局映射是一种软件 bug,在切换到具有该地址范围的不同非全局映射的地址空间后,可能会不可预测地导致使用任一映射
全局映射不需要冗余地存储在多个对应不同 ASID 的 TLB 中。此外,当执行 SFENCE.VMA 指令时,如果 ,则 G 为 1 的条目不需要从 TLB 刷新掉
RSW:保留供主管软件使用;硬件实现忽略
每个叶 PTE 都包含下面两个位:
A:是否可访问。A 位表示自上次清除 A 位以来该页是否发生过 read、written 或 fetched
D:是否脏。D 位表示自上次清除 D 位以来该页是否发生过 written
下面有两种被允许的管理 A 和 D 位的方法:
-
当访问虚拟页面并且 A 位为 0,或者写入并且 D 位为 0 时,会引发 page fault 异常
-
当虚拟页面被访问并且 A 位为 0,或者被写入并且 D 位为 0 时,硬件实现在 PTE 中设置相应的位。相对于对 PTE 的其他访问,PTE 更新必须是原子的,并且必须原子地检查 PTE 是否有效并授予足够的权限。A 位的更新可以作为猜测的结果来执行,但对 D 位的更新必须是精确的(即,不是推测的),并且可被本地 hart 按程序顺序观察到。此外,PTE 更新必须在不迟于显式内存访问或本地 hart 对该虚拟页面的任何后续显式内存访问的情况下以全局内存顺序出现。FENCE 指令提供的加载和存储顺序以及原子指令上的获取/释放位也会命令与远程 harts 观察到的这些加载和存储相关的 PTE 更新。对于导致更新的显式内存访问,PTE 更新不需要是原子的,并且序列是可中断的。但是,在 PTE 更新全局可见之前,hart 不得执行显式内存访问
简单总结就是,一种是软件修改,一种是硬件修改。所有的 hart 都必须使用同一种策略。所有的硬件实现都不能对 A 和 D 位进行清零操作
任何级别的 PTE 都可以是叶子 PTE,因此除了 4 KiB 页面之外,Sv39 还支持 2 MiB 兆页和 1 GiB 千兆页,每个千兆页都必须虚拟和物理地与与其大小相等的边界对齐。如果物理地址对齐不足,则会引发 page fault 异常
对于非叶 PTE,D、A 和 U 位保留用于未来的标准使用。在标准扩展定义它们的使用之前,它们必须由软件清除以实现前向兼容性
对于基于页面的虚拟内存和“A”标准扩展的实现,LR/SC 预留集必须完全位于单个基页内(即自然对齐的 4 KiB 区域)
虚实地址转换过程
虚拟地址 va 被转换为物理地址 pa 的过程如下所示:
-
设 ,设 。(对于 Sv39 而言:页大小为 4KiB,也就是 ,也就是将 左移 12 位;VPN 有三项,则 。)satp 寄存器必须是运作的,即当前特权模式必须是 S 模式或 U 模式
-
设 为内存中地址为 的数据的值。(对于 Sv39 而言,每个 PTE 是 64bit,,所以 PTESIZE 为 8。)如果访问 PTE 的地址违反了 PMA 或者 PMP 检查,则引发与原始访问类型对应的 access fault 异常
-
如果 ,或者 和 ,或者如果在中设置了为未来标准使用保留的任何位或编码,则停止并引发与原始访问类型对应的 page fault 异常
-
否则,PTE 有效。如果 或 ,则转到步骤 5。否则,此 PTE 是指向页表下一级的指针。让 。如果 ,则停止并引发与原始访问类型对应的 page fault 异常。否则,让 并转到步骤 2
-
已找到叶 PTE。根据当前特权模式以及 mstatus 寄存器的 SUM 和 MXR 字段的值,确定 、、和 位是否允许内存访问请求。如果不是,则停止并引发与原始访问类型对应的 page fault 异常
-
如果 并且 ,则这是一个未对齐的超级页;停止并引发与原始访问类型对应的 page fault 异常
-
如果 ,或者原始内存访问是 store 并且 ,则引发与原始访问类型对应的 page fault 异常,或者:
-
如果存储到 pte 会违反 PMA 或 PMP 检查,则引发与原始访问类型对应的 access fault 异常
-
原子地执行以下步骤:
- 将 pte 与内存中地址为 的 PTE 值进行比较
- 如果值匹配,则将 设置为 1,如果原始内存访问类型是 store,则将 设置为 1
- 如果比较失败,返回步骤 2
-
-
翻译成功。翻译后的物理地址如下:
-
-
如果 ,则这是一个超级页面翻译,
-
-
该算法对地址转换数据结构的所有隐式访问都是使用宽度 执行的,对于 Sv39 而言,该值为 64
步骤 2 中隐式地址转换读取的结果可以保存在只读、不一致的 TLB 中(不同 harts 的 TLB 条目内容不一致),但不与其他 harts 共享。TLB 可以保存任意数量的条目,包括任意数量的相同地址和 ASID 的条目。如果 TLB 条目关联的 ASID 与步骤 0 中加载的 ASID 匹配,或者如果 TLB 条目的 G 位为 1,则 TLB 中的条目可以满足后续的步骤 2 读取。为了确保隐式读取观察对相同内存位置的写入,必须在写入后执行 SFENCE.VMA 指令以刷新相关的缓存转换
TLB 不能在步骤 7 中使用;访问和脏位只能直接在内存中更新
允许多个 TLB 条目为同一地址共存。这表明在传统的 TLB 层次结构中,多个条目可能匹配单个地址,例如,如果一个页面升级到超级页面而不首先清除原始非叶 PTE 的有效位并执行 的 SFENCE.VMA,或者如果多个 TLB 在层次结构的给定级别并行存在。在这种情况下,就像在写入内存管理表和随后隐式读取相同地址之间没有执行 SFENCE.VMA 一样:使用旧的非叶 PTE 还是新的叶 PTE 是不可预测的,但行为是明确定义的
只要 satp 处于活动状态(如 satp 寄存器活动性判定 所定义),硬件实现可以在任何时候对任何虚拟地址推测性地执行地址转换算法。这种推测性执行具有预填充 TLB 的效果
地址转换算法的推测执行与算法的非推测执行一样,只是它们不能为 PTE 设置脏位,不能触发异常,并且如果自算法的推测执行开始以来,这些条目会被 hart 执行的任何 SFENCE.VMA 指令无效,则它们不能创建 TLB 条目
伪代码
1 | |
图解
在我的实现中,PPN 的宽度为 22,因为我的 AXI 地址大小就只有 32 位。图里的宽度 44 应该改成 20
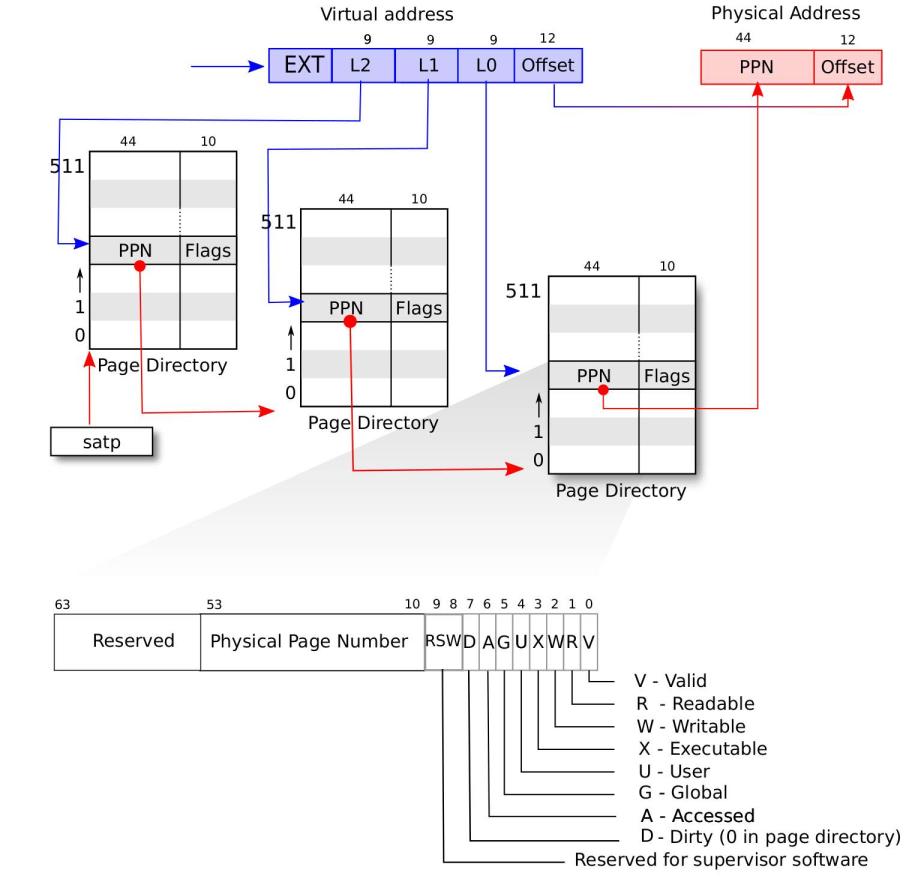
假设每次访问都没有发生异常并且访问的页大小始终为 4KiB,那么整个过程如下:
-
先使用 satp.ppn << 12 得到了根页表的地址,将根页表地址加上 va.vpn[2] * 8 的偏移量,使用这个地址读取内存,可以得到包含指向下一级页表的根地址的页表项
-
将页表项里的 PPN 左移 12 位,得到了一个 32 位的地址,并加上 va.vpm[1] * 8 的偏移量,使用这个地址读取内存,可以得到包含指向下一级页表的根地址的页表项
-
将页表项里的 PPN 左移 12 位,得到了一个 32 位的地址,并加上 va.vpm[1] * 8 的偏移量,使用这个地址读取内存,可以得到最终的物理地址;而这个物理地址就是我们虚实翻译的 PPN 的结果,使用它拼接上页偏移就能得到 32 位物理地址了
TLB 的实现
目前我还没实现 TLB,下面只是我理论上的设计,先写出来理一下思路
考虑使用全相连的结构设计 TLB,发生 miss 时使用随机替换的方法进行 TLB 条目更新
条目
应该包含:ASID、PPN、VPN、Flag
1 | |
虚实地址转换
未启用
先看此时是否启动了虚实地址转换的功能,如果没有启动的话,就不需要虚实地址转换。此时的 VPN 就是 PPN,当然还得检查 VPN 比 PPN 多出来的高位是不是 0
启用
如果启用了虚实地址转换功能,那么就先使用 VPN 比较所有的 TLB 条目,VPN 一致且 ASID 一致或者 G 为 1 并且 V 为 1 时,TLB 成功命中,直接使用该 TLB 条目内的 PPN 即可,当然还要关注其它的标志位,条件都满足的话就完成了虚实翻译,不满足标志位的访问要求时要抛出 page fault 异常
假如 TLB 没有命中,此时需要 PTW(Page Table Walker)部件进行 TLB 重填,PTW 部件会按照 虚实地址转换过程 所描述方法访问三次内存最后读到页表项,并将页表项填入 TLB 里
PTW 集成在 DCache 中,通过 DCache 模块的 AXI 接口进行访存
SFENCE.VMA 指令

该指令用于将内存中的内存管理数据结构的更新与当前执行同步,通俗的说就是在操作系统更新了页表项后需要使用该指令使得硬件的 TLB 与页表项同步
例外触发
只有 mstatus 寄存器中的 TVM(Trap Virtual Memory)位的值为 0 时,在 S 模式下才可以读写 satp 寄存器或者执行 SFENCE.VMA 或者执行 SINVAL.VMA 指令;如果值为 1,则在 S 模式执行上面的操作都会导致 illegal instruction 例外
如何实现
rs1 和 rs2 不同取值时的区别如下:
情况一: 且
清空 TLB,即将所有的 TLB 的有效位置为 0
情况二: 且
对所有与 rs2 指示的 asid 值一致的 TLB 项的有效位置为 0,如果 TLB 项的 G 位为 1,则不用置为 0
情况三: 且
对所有与 rs1 指示的 vaddr 值一致的 TLB 项的有效位置为 0
情况四: 且
对所有与 rs1 指示的 vaddr 值一致且与 rs2 指示的 asid 值一致的 TLB 项的有效位置为 0,如果 TLB 项的 G 位为 1,则不用置为 0